Algoritmos de Laberintos en Java: Generación y Pathfinding en JavaFX
La guía definitiva de algoritmos de laberintos en JavaFX. Aprende todo sobre la generación (Backtracker, Prim, Kruskal) y resolución (BFS, Algoritmo A*) paso a paso.
JJ Arroyo
7 de marzo de 2026 • 15 min de lectura
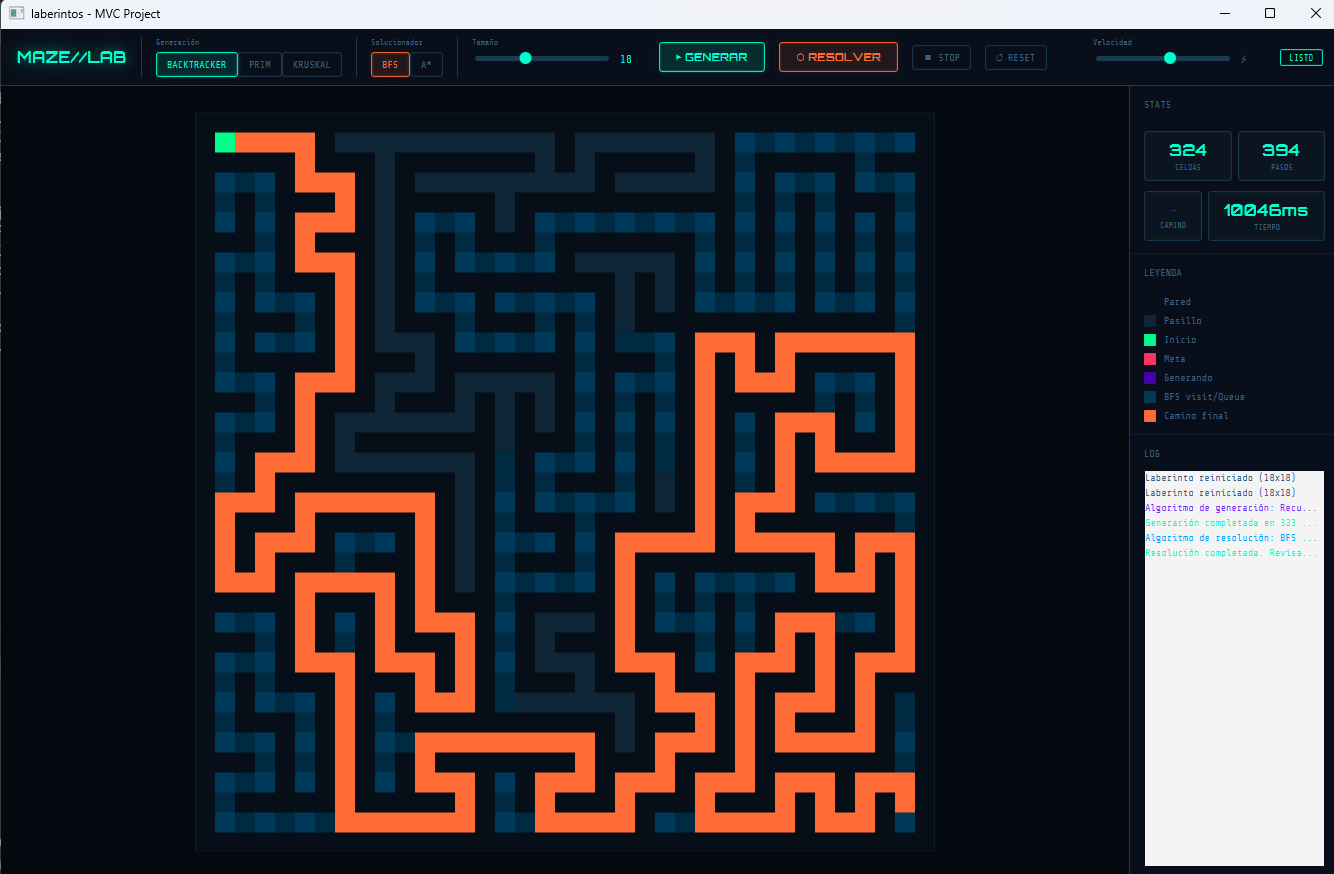
¿Alguna vez te has preguntado cómo los videojuegos generan mapas procedurales o cómo la inteligencia artificial encuentra la salida de un laberinto en milisegundos? Desarrollar un generador y solucionador de laberintos interactivo en Java es uno de los proyectos más fascinantes para dominar la teoría de grafos, estructuras de datos y algoritmos de pathfinding.
En esta guía definitiva, exploraremos cinco algoritmos fundamentales implementados paso a paso en JavaFX. Analizaremos el código lógico, el rendimiento y por qué cada uno produce patrones geométricos completamente únicos que puedes usar en tus propios juegos y proyectos.
🏗️ Algoritmos de Generación de Laberintos (Maze Generation)
Para construir un laberinto mediante programación, partimos de una cuadrícula bidimensional (una grilla) donde cada celda lógica está rodeada por muros intactos. El objetivo de los algoritmos de generación de laberintos es derribar muros matemáticamente hasta crear un grafo conexo perfecto y sin ciclos.
A continuación, analizamos los 3 mejores algoritmos para generar laberintos en Java y JavaFX.
1. Algoritmo Recursive Backtracker (Búsqueda en Profundidad - DFS)
El Recursive Backtracker es el algoritmo más popular para crear laberintos. Al estar basado en el recorrido en profundidad (DFS o Depth-First Search), crea "ríos largos"; caminos muy serpenteantes con pocos callejones sin salida, ideal para juegos de exploración tipo RPG.
Estructuras de datos utilizadas en Java:
- Una Pila (
Stack) para rastrear el recorrido y poder retroceder de manera eficiente. - Una Matriz bidimensional (
boolean[][]) para registrar las celdas ya visitadas.
Cómo funciona el Backtracking paso a paso:
- Haces un push de la celda de inicio a la pila y la marcas como "visitada".
- Revisas la celda en el tope de la pila (
peek()). Si de esa celda quedan vecinos no visitados, eliges uno de ellos aleatoriamente. - Rompes el muro que los divide (
CellState.PASSAGE), marcas al vecino como visitado y lo apilas, adentrándote velozmente por la estructura del grafo. - Si te topas con un callejón sin salida (ningún vecino válido), sacas el elemento actual de la pila (
pop()), haciendo un retroceso sistemático (Backtracking) hasta hallar una encrucijada con caminos inexplorados y retomas el avance.
[!TIP] Rendimiento: Este algoritmo es extremadamente rápido y sencillo de implementar, pero su uso intensivo de la pila lo hace propenso a errores StackOverflow si se implementa recursivamente en mapas muy masivos en lugar de manera iterativa.
2. Algoritmo de Prim: Generación de Laberintos Radiales
Si buscas laberintos que parezcan expandirse radialmente, con un aspecto algorítmico natural similar al crecimiento de células, repleto de incontables callejones muy cortos e intrincados, el Algoritmo de Prim es la respuesta.
Al contrario de la naturaleza profunda del DFS, Prim tiene una expansión aleatoria difusa. No hay un "caminante" único rompiendo muros continuamente; en cambio, el laberinto devora su terreno colindante desde las múltiples fronteras a la vez.
Estructuras de datos óptimas:
- Lista de Fronteras (
List<Position> frontier) candidatas que aún no han sido anexadas. - Matriz booleana de elementos in-laberinto.
Lógica del algoritmo de Prim en Java:
- Agregas una celda central o de inicio a la lista de componentes del laberinto. Todas las celdas adyacentes a esta, se consideran "Fronteras".
- De todas las fronteras listadas, eliges una completamente al azar.
- De sus vecinos que ya son parte del laberinto, seleccionas uno aleatorio, rompes el muro conector y unes la nueva celda al conjunto del laberinto.
- Los vecinos de esta nueva conquista pasan a ser insertados a la gran lista de Fronteras, listos para un posible sorteo.
- Este ciclo continúa hasta que la lista de Fronteras se vacía, asegurando un recorrido total de las celdas.
Diseñar juegos con este algoritmo asegura un altísimo nivel de frustración geográfica, ¡las bifurcaciones sobran!
3. Algoritmo de Kruskal (Árbol de Expansión Mínima - MST)
Si Prim suena caótico, el Algoritmo de Kruskal es magia matemática pura. Visualmente carece de un único núcleo de crecimiento, y en su lugar, rompe muros totalmente arbitrarios e inconexos por toda la pantalla, creando senderos diminutos y huérfanos. No obstante, al final todo encajará como un puzzle mágico, convirtiéndose en un laberinto perfecto sin celdas muertas ni lazos erráticos.
Esto lo logra calculando un Minimum Spanning Tree (MST).
Estructuras de datos:
- Algoritmo de Conjuntos Disjuntos (Union-Find Data Structure).
- Una Lista general barajada (
Collections.shuffle) de todos los muros posibles en el área visual.
Implementación de Kruskal para desarrolladores:
- Asignas a cada celda de tu mundo bidimensional un identificador abstracto único (
id = y * width + x). Al comienzo, consideras que todas pertenecen a "su propio árbol". - Tomas la lista completa de todos los muros que hay en el mundo y la ordenas al azar.
- El iterador entra y toma un muro de manera secuencial: Para las dos celdas que ese muro particular divide, empleas la función
find()para preguntarle al Union-Find de qué árbol provienen. - ¿Son distintos árboles? Entonces derribamos el muro, ya que hay un camino fresco que conecta elementos aislados. Inmediatamente usamos
union()asociando todos sus futuros componentes. - ¿Resulta que
find()reporta el mismo árbol en ambas orillas? Si tumbáramos esa pared crearíamos un ciclo cerrado (anillo) en el laberinto, frustrando la ley de su topografía conexa; por lo tanto, ignoramos esa pared manteniéndola sellada de por vida.
🧠 Algoritmos de Resolución de Laberintos (Pathfinding)
Poseer el laberinto constituye solo la mitad del desafío del software inteligente. Ahora corresponde dotar a la computadora con la facultad lógica capaz de encontrar la remota salida operando entre las posiciones (0,0) hasta (rows - 1, cols - 1). ¡Demos la bienvenida a los asombrosos algoritmos de Pathfinding!
1. BFS (Búsqueda en Anchura - Breadth-First Search)
El Algoritmo BFS es el detector de rutas ciego pero absolutamente inquebrantable. A diferencia del atrevimiento individual de DFS, el BFS procede de manera metódica, sistemática y nivel por nivel. Inspecciona su área de manera circular, simulando el pulso que generaría la perturbación concéntrica de un cuerpo hundiéndose en aguas en reposo; nada escapa a su sondeo simultáneo.
- ¿Por qué debes conocerlo? BFS jamás fallará si tu objetivo es encontrar matemáticamente la ruta más corta absoluta a tu destino, suponiendo que todos los pasos cuenten con igual costo ponderado.
- ¿Cuál es la debilidad de este método? No sabe por donde ir. Se va a desviar inútilmente para examinar vías laterales desoladas del laberinto, despilfarrando de ese modo importantes ciclos de procesador (
CPU Time) y muchísima memoria de entorno. - Su arquitectura en Java: Su cimiento cardinal asume la forma de una Cola (
Queuede la convención First In, First Out). Las posiciones recientes deben esperar de manera estricta al final de dicha cola, dándole primero la oportunidad resolutiva a los ramales geográficos que fuesen los primeros en ser hallados.
2. Algoritmo A* (A-Star Search Algorithm): Inteligencia Artificial de Alto Nivel
El Algoritmo A* constituye la gema incalculablemente valorada en la arquitectura moderna de pathfinding e inteligencia preprogramada en videojuegos de última generación. Enlaza los atributos positivos del recorrido óptimo con el agregado majestuoso que provee "una nariz capaz de oler el destino cercano"; volviéndolo imbatiblemente certero.
A* somete a prueba la eficiencia de cada cuadrante accesible atribuyéndole una calificación precisa regida por la siguiente formulación heurística matemática:
F = G + H
G(Costo Certificado): Medición de la suma de unidades avanzadas desde el sitio de eclosión original hasta la encrucijada presente evaluada.H(Heurística o Distancia Manhattan): Valuación predictiva pura e intuitiva que calcula cuánto trecho falta recorrer directamente hacia la bandera final. Generalmente se aproxima abstrayendo visualmente un vuelo de pájaro recto así:h = |x1 - x2| + |y1 - y2|.
El corazón del engranaje Java para este ente artificial depende fuertemente de una Cola de Prioridades (PriorityQueue<Node>), a cargo de desenrollar permanentemente aquellos candidatos cuyo índice tabulado recaiga con el mérito más bajo posible de la ponderación F (A* buscará obstinadamente propiciarse de un costo numérico infalible del menor grado posible). De esta forma, fluye de un modo calculador hacia la salida, negándose rotundamente a derrochar el lapso evaluando rincones perdidos contrarios a su latitud impuesta.
💻 Descarga el Proyecto Completo (Archivos y Código en JavaFX)
Comprender la semántica algorítmica y su modelo matemático es vital, sin embargo, contemplar las implementaciones algorítmicas compitiendo ferozmente por desenredar las intrincadas marañas sobre una aplicación programada al cien por ciento en JavaFX no tiene valor equiparable.
Nuestra aplicación dispone de visualizaciones orgánicas, iteraciones milimétricas del bucle fundamental asíncrono y componentes envueltos en impresionantes variables CSS del patrón Dark Mode extraídos desde un paradigma MVC que emplea nuestra aclamada utilidad gráfica jjarroyo-library.
📌 Preguntas Frecuentes (FAQ)
¿Cuál es el mejor algoritmo general para la generación arquitectónica de un laberinto cerrado?
Esto decae unánimemente en la funcionalidad requerida de su estructura base. Si te agradan los sinuosos ríos de un solo paso de ancho propicios en la exploración RPG, aférrate a las bondades directas del Recursive Backtracker. Si deseas laberintos complejos repletos de la irritación mental producto de una colmena confusa y de minúscula bifurcación que cause tropiezos a cada bloque métrico superado, anéxate firmemente del núcleo matemático del Algoritmo de Prim. Si tus planes anhelan un ensanchamiento uniforme, inescrupulosamente orgánico e impredecible en sus simetrías internas, el patrón del Union-Find resuelto con Kruskal te proporcionará el lienzo base.
¿A qué se debe que BFS adquiera una desventaja exponencial en rendimiento práctico contra A* en el hallazgo de nodos finales?
Debido netamente a la carencia flagrante de una métrica predictiva Heurística. En un suceso base de evaluación temporal el iterador del componente BFS va invariablemente a consumir los recursos limitados en medir una amplia diversidad de posibles bifurcaciones en direcciones por naturaleza antitéticas al paradero final deseado, pues el sistema ignora lógicamente en su concepción matemática la procedencia local o latencia cardinal de tu bandera buscada, siendo un simple expansor circular abarcando infinitas posibilidades muertas hasta toparse visualmente de cara a cara con su término conclusivo.
¿Cual es la asimetría esencial de Pathfinding entre BFS vs DFS?
Haciendo a un lado la capacidad de generar muros cerrados de la derivación del DFS, las utilidades puestas de cara resolver grafos complejos declaran que BFS inspecciona a todas sus inmediaciones nivel por nivel en pos al aseguramiento fidedigno y perimetral de obtener irrefutablemente el encaje numérico correlativo en el vector escalar más estrecho hacia la recta final; caso opuesto sucede con el ruteo propio subyacente a los cimientos abstractos de DFS, pues éste opta inquebrantablemente a viajar testarudo lo más recóndito y ciegamente hondo, empujando y sumando iteraciones continuas del trayecto perdiendo instantáneamente los beneficios del óptimo atajo; pudiendo entregar trayectorias ganadoras irrisoriamente excesivas perdiendo totalmente fiabilidad para usos profesionales del vector meta.
Pon en marcha de inmediato la codificación práctica y visual de este puñado de conocimientos, dominando sin titubeos estos magistrales paradigmas algorítmicos. ¡Si te ha sido de inmensa asimilación este estudio pormenorizado compártelo con más desarrolladores colegas amantes de Java, y examina detenidamente nuestras múltiples piezas anexas en lo correspondiente al universo ilustrativo de los portlets de JavaFX!